Meaningful Versions with Continuous Everything
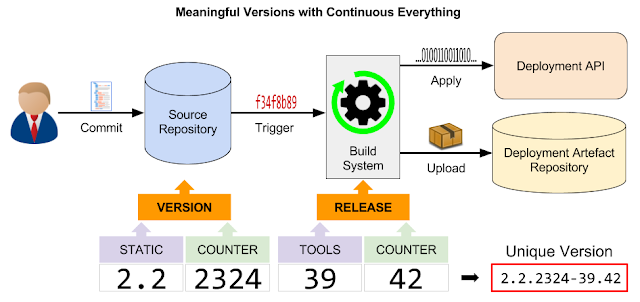
Q: How should I version my software? A: Automated! All continuous delivery processes follow the same basic pattern: Engineers working on source code, configuration or other content commit their work into a git repository (or another version control system, git is used here as an example). A build system is triggered with the new git commit revision and creates binary and deployment artefacts and also applies the deployments. Although this pattern exists in many different flavors, at the core it is always the same concept. When we think about creating a version string the following requirements apply: Every change in any of the involved repositories or systems must l ead to a new version to ensure traceability of changes. A new version must be sorted lexicographically after all previous versions to ensure reliable updates. Versions must be independent of the process execution times (e.g. in the case of overlapping builds) to ensure a strict ordering of the artef...
